
日前,《国家科学评论》(National Science Review,NSR)在线发表了由北京大学信息科学技术学院、高可信软件技术教育部重点实验室崔斌教授课题组与腾讯数据平台部合作撰写的论文《一种新型大规模分布式机器学习体系Angel》(Angel: a new large-scale machine learning system,DOI: 10.1093/nsr/nwx018)。这是首篇刊登在NSR的信息科学领域研究论文。
文章回顾了学术界和工业界近期共同关注的机器学习体系,偏重介绍了Angel体系的设计思想和实现细节,并通过对多个大规模数据集上不同机器学习算法和体系的比较,验证了Angel体系在分布式机器学习方面的有用性。
现有的机器学习体系都是针对不同类型的机器学习义务而搭建的。数据流体系Hadoop和Spark适用于通用的数据处理义务和构建机器学习流水线,但缺乏参数共享机制,存在单点瓶颈性能题目;图计算体系GraphLab、GraphX和Tux2等将机器学习计算抽象成图结构,可行使图结构的特征加速,但只适合具有稀少图结构的算法;深度学习体系TensorFlow、MXNet和Caffe2等行使参数服务器或全局归约进行分布式神经网络的训练,可行使GPU对神经网络的计算加速,但缺乏对稀少图结构的优化和支撑。
由北京大学-腾讯协同创新实验室开发的开源体系Angel(源代码见https://github.com/Tencent/angel)兼顾工业界的高可用性和学术界的创新性,集成和优化多种机器学习算法,是一个基于参数服务器理念的分布式机器学习框架,使机器学习算法在高维度模型上轻松运行。它围绕模型共享的核生理念,将高维度的大模型合理地切分到多个参数服务器节点,并通过高效的模型更新接口、运算函数和多变的同步协议实现各种高效的机器学习算法。得益于优秀的设计,Angel既能自力运行、高效实行多种机器学习算法,也能作为参数服务器服务,支撑Spark和现有深度学习框架,并为其加速。联合课题组基于工业界的海量数据,反复实践和调优,使得Angel具有广泛的适用性和稳固性,模型维度越高,上风越显明。经过在真实数据集上的对比,Angel在多种机器学习算法上的性能优于XGBoost、Spark、Petuum、TensorFlow等常用机器学习体系,已被应用于腾讯视频点击展望和广告保举等现实营业中。
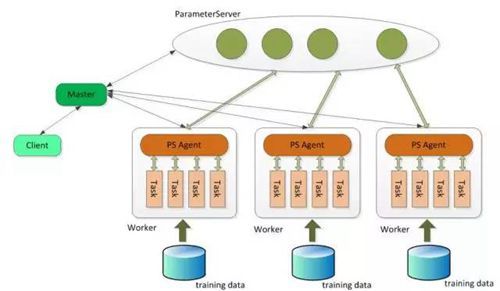
Angel体系框架
Angel目前基于Java和Scala开发,将来还将加入Python等多种语言接口,使用更便捷,且参数服务器服务能力会进一步提拔,支撑图计算和深度学习框架。
编辑:山石
下一篇::北京大学邓宏魁及柴真研究组在Cell Stem Cell杂志上发表紧张研究成果建立细胞谱系重编程的新方法
- 2017年天津大学成人高等教育招生简章
- 北京化工大学2018年成人高考招生简章
- 北京农学院2018年成人高等教育招生简章
- 2018年北京服装学院成人高考招生简章
- 北京第二外国语学院继续教育学院成考招生简章
- 中国人民公安大学2018年成人高考招生章程
我有话说
最新文章
- 1教育部专家组来我院开展基本

根据教育部工作部署,2018年5月24日教育部直......
- 2北京市委常委、宣传部部长杜
7月16日下午,中共北京市委常委、宣传部部长......
- 3焦宁教授研究团队在醇类分子
2018年7月6日,NatureCommunications(《自然......
- 4Nature Biotechnology报道生
2018年7月9日,北京大学生命科学学院、北大-......
- 5物理学院吕劲团队发现新型二
近年来,半导体行业总是笼罩在摩尔定律难以为......
热门文章
- 1电镜实验室高鹏等在最薄的钙钛矿
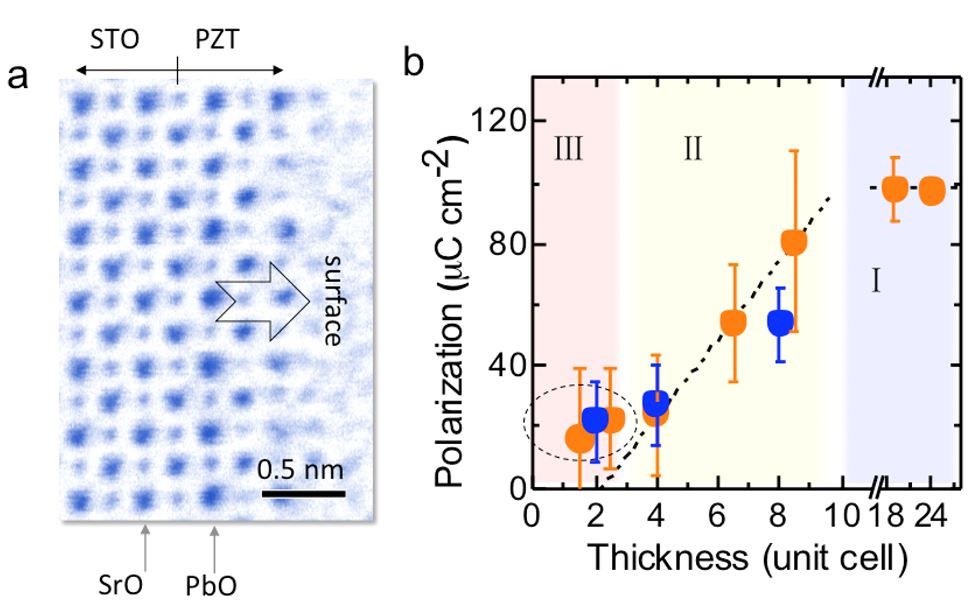
铁电薄膜在数据储存、传感、表面催化等方面...
- 2北京大学-腾讯协同创新实验室关于
日前,《国家科学评论》(NationalScienceRev...
- 3北京大学乔杰和汤富酬团队合作研

2017年4月27日,北京大学第三医院乔杰教授团...
- 4信息学院杨玉超研究员黄如院士课
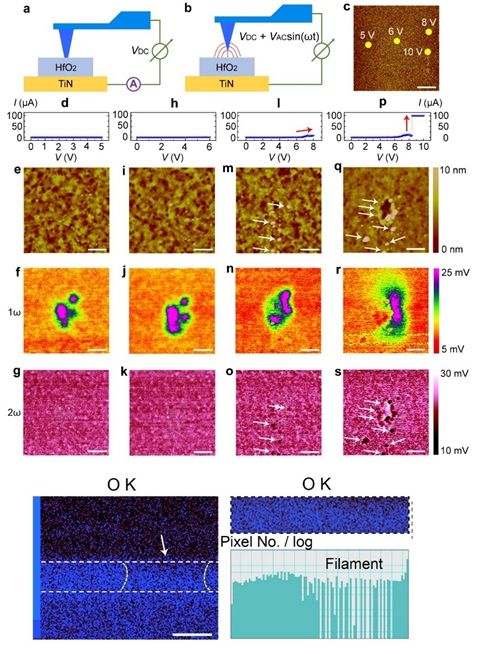
忆阻器是近年来备受关注的新型纳米器件,在新...
- 5工学院陈匡时课题组在单分子成像

最近,北京大学工学院生物医学工程系陈匡时课...

